It seems that everyone is in a race to build AI Agents—we all want to be Makers. Low-code tools are making it ever easier to build AI agents. However, unless users can trust the Agent output, they will not adopt AI agents in the enterprise. This is why measuring the quality of AI agents is of paramount importance.
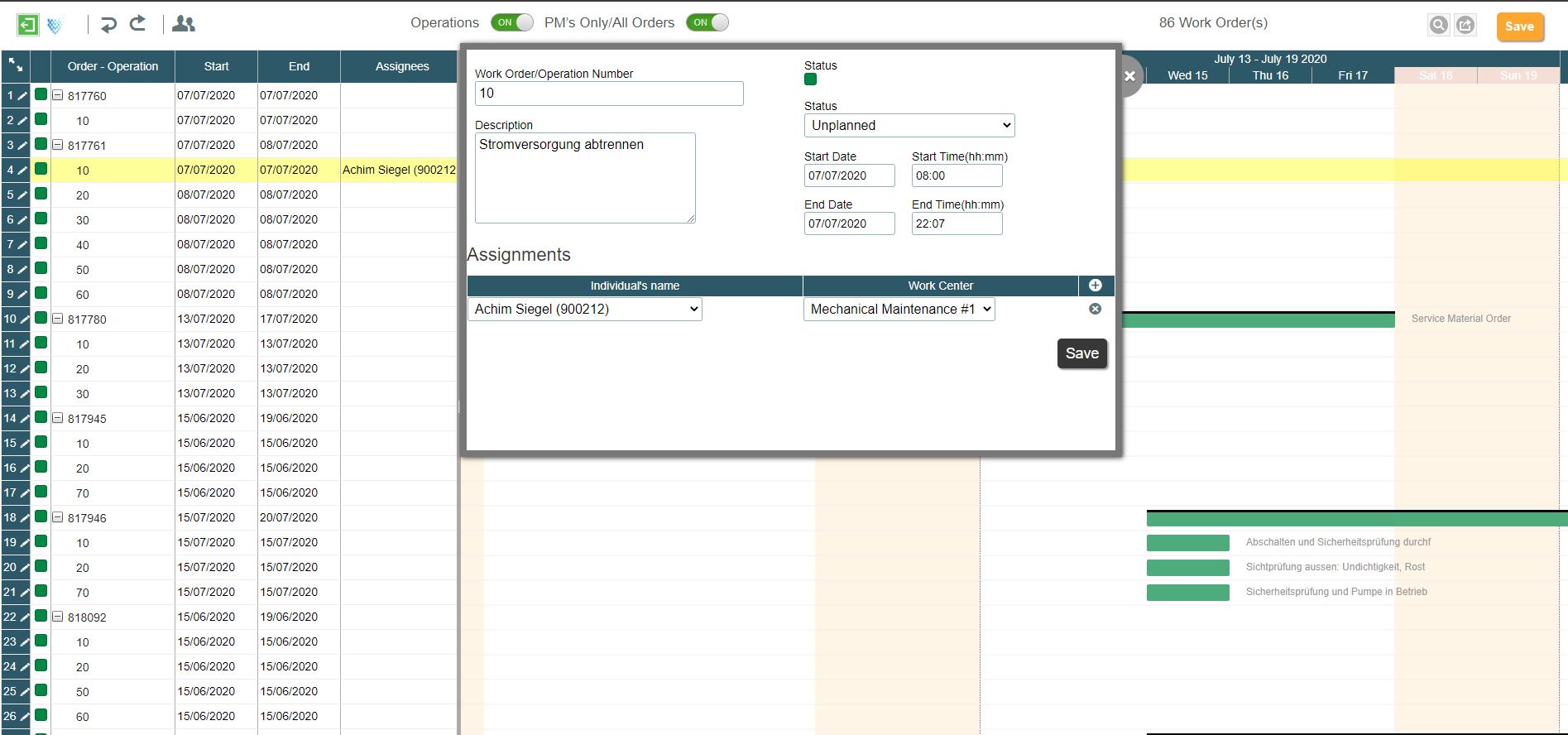
One effective way to measure the quality of agent outcomes is through Evaluation in Microsoft Copilot Studio. I recently attended a webinar by Microsoft and also spoke with experts who focus on evaluating agent behavior.
Here is what you need to know about measuring Agent quality in general and Evaluation in Copilot Studio:
AI Agent Evaluation
AI Agent Evaluation is the process of measuring how well an agent performs its intended tasks. Unlike traditional software testing, which typically results in a binary Pass/Fail outcome, agent evaluation is a multi-dimensional assessment of quality.
Evaluation Goals
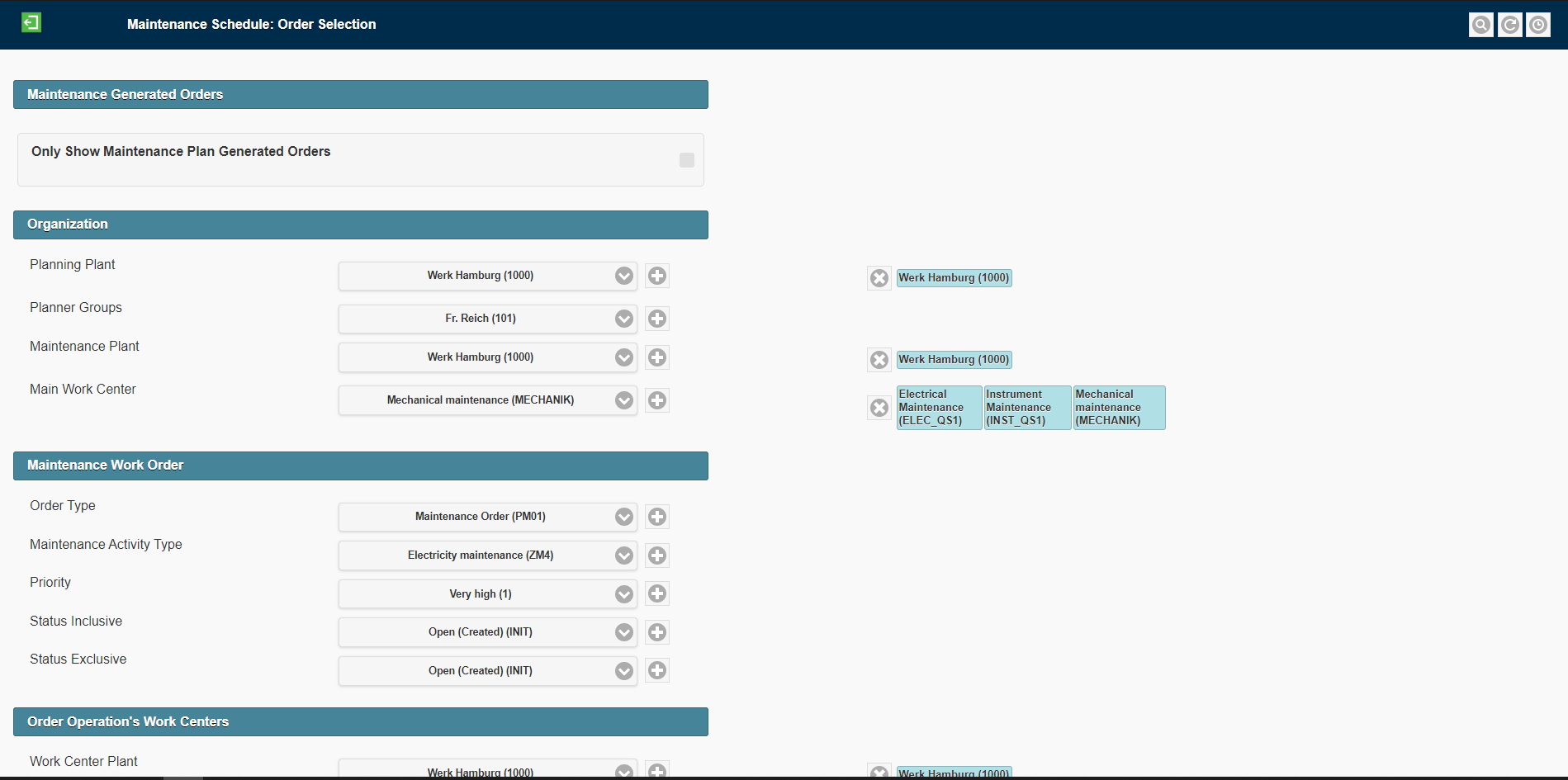
These should be defined up-front. The core mission of the agent in terms of what tasks it has to perform and the success metrics from both a business and user perspective, should be defined. The scope and boundaries of the agent needs to be articulated. The key scenarios need to be stated clearly in terms of the essential use cases that the agent needs to execute.
Evaluation Framework
Microsoft recommends a four-stage framework: Core, Baseline, Expand, and Operationalize. The process begins by defining test cases for key scenarios, running evaluations, identifying gaps, and iterating until goals are met. From there, coverage can be expanded to include edge cases, and finally automated to support continuous quality testing.
-
Stage 1: Define Quality Signals, Key Scenarios, Test Cases, and Acceptance Criteria.
-
Stage 2: Run core test cases, analyze failures, improve agent behavior, and re-evaluate.
-
Stage 3: Expand testing across categories such as Regression, Variations, Architecture, and Edge Cases. Edge case and robustness testing includes boundary conditions, adversarial inputs, and scenarios where the agent should decline to respond.
-
Stage 4: Define an evaluation cadence to enable confident iteration when changes occur—such as model upgrades or major knowledge base updates.
All four stages can be executed using Evaluation in Copilot Studio.
Evaluation in Microsoft Copilot Studio
Copilot Studio provides several features that help measure agent quality:
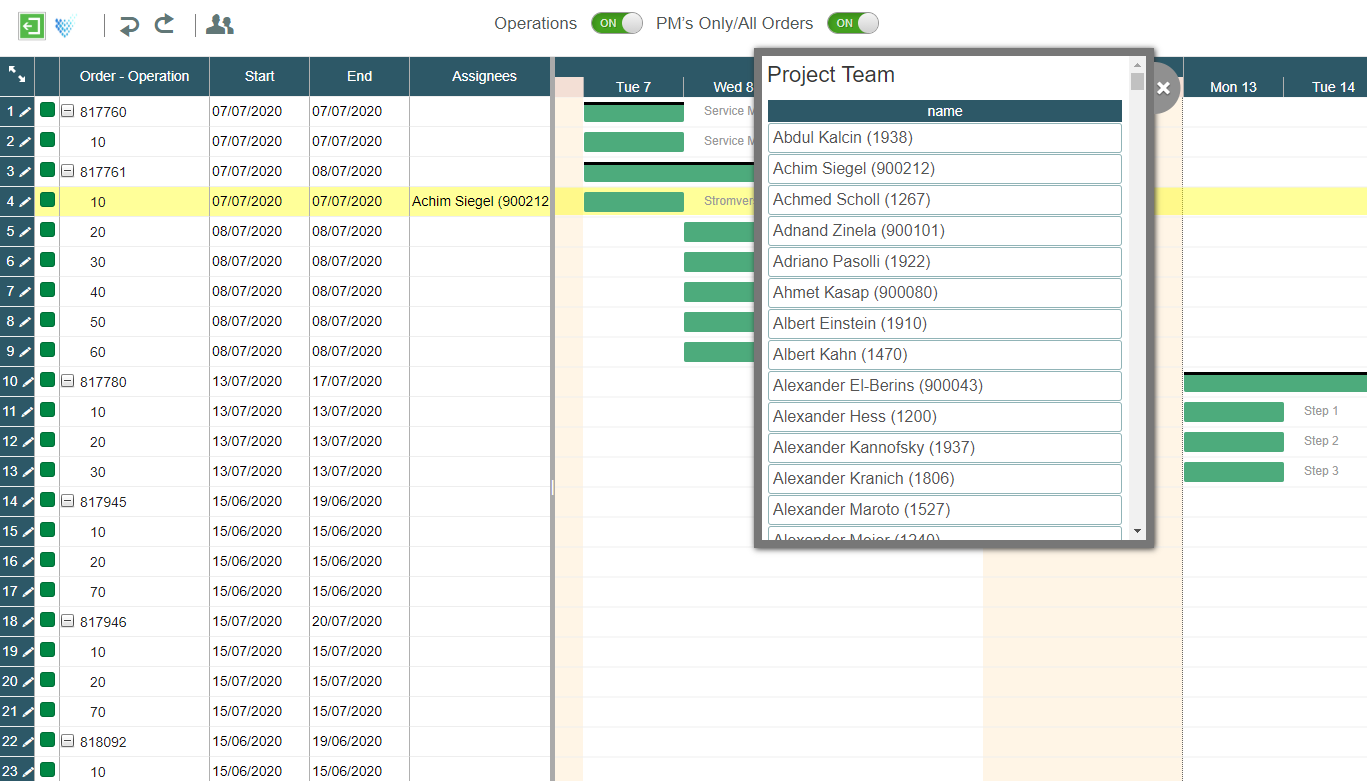
- Dataset generation: Create datasets manually, import existing test cases, or auto-generate test cases using AI.
- Test Methods: There are various test methods, including General Quality, Compare Meaning, Keyword Match, Text Similarity, Exact Match, Capability Use, and Custom/ Classification. Classification Graders are really helpful as they enable the user to define the evaluation logic by giving instructions using natural language and creating labels.
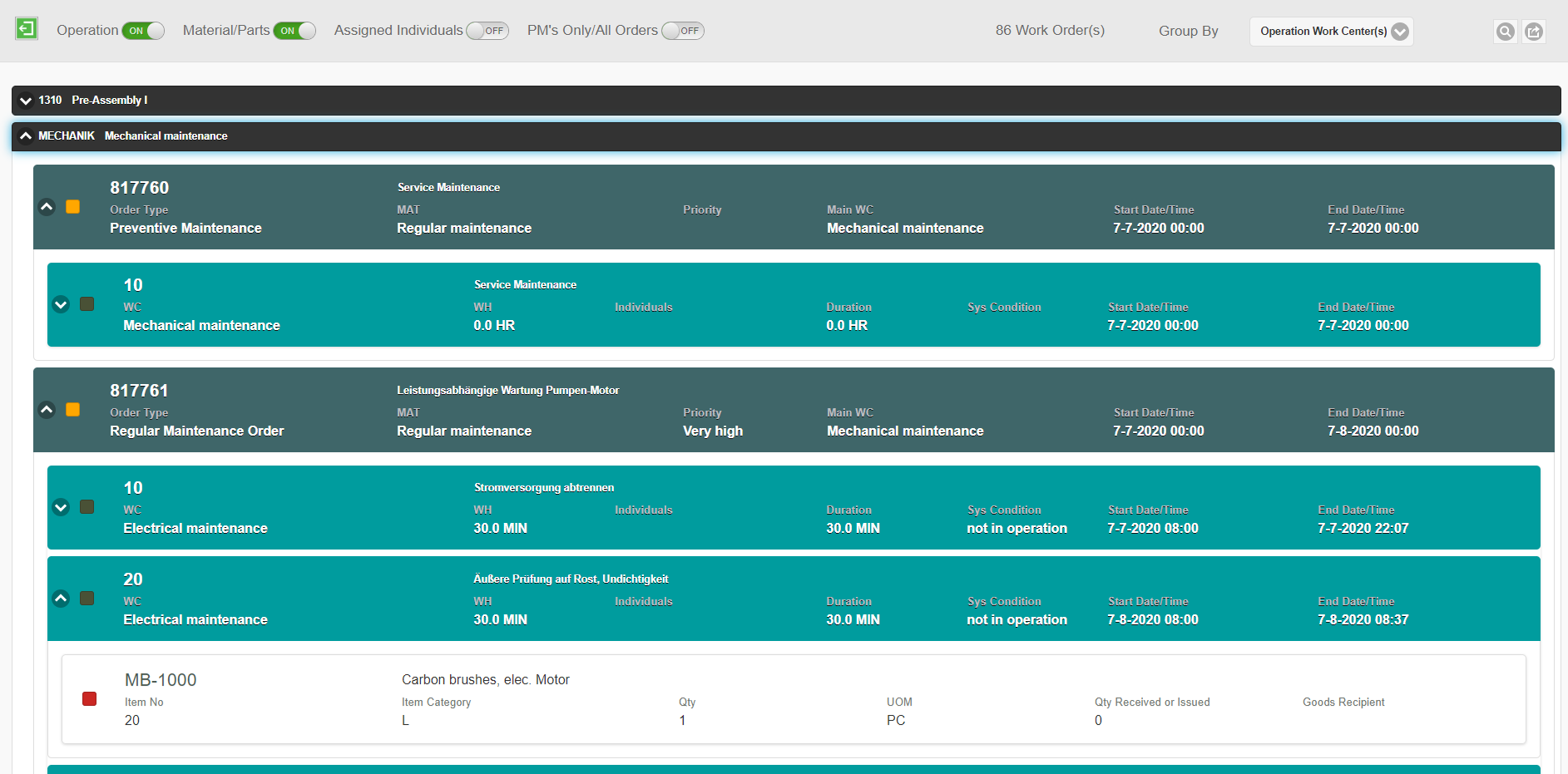
- Detailed Test Results: The test results have Pass/Fail, Labels, failure reason, and more.
In summary, evaluating AI agents is essential before deploying them to production. Microsoft Copilot Studio Evaluation is purpose-built to support this need. We strongly recommend leveraging this functionality to build trust and drive user adoption of the agents you create. We will certainly be using these evaluation capabilities in the AI agents that Unvired is building on Microsoft Copilot Studio.
If you are exploring how to design, evaluate, or operationalize AI agents that users can truly trust, Unvired can help you accelerate that journey—from agent strategy and evaluation design to production rollout. Contact us today!